
pythonでエクセルファイルを読み込むサンプルコード(実践的)を作成しました
これは下の記事のコードを改良したものです
まずはこちらをご覧ください

コード
import pandas as pd
def create_line_and_column_header_dict(
book,
sheet=0,
column_header=1,
row_header=1,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [row_header+1, column_header+1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[row_header-1] + [i for i in range(cell_start[0]-1, cell_end[0])],
header=column_header-1,
index_col=0,
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(column_header, cell_start[1]-1)]
)
return df.fillna("NA").to_dict(orient="index")
def create_column_and_line_header_dict(
book,
sheet=0,
column_header=1,
row_header=1,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [row_header+1, column_header+1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[row_header-1] + [i for i in range(cell_start[0]-1, cell_end[0])],
header=column_header-1,
index_col=0,
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(column_header, cell_start[1]-1)]
)
return df.fillna("NA").T.to_dict(orient="index")
def create_line_header_dict(
book,
sheet=0,
row_header=1,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [row_header+1, 1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[row_header-1] + [i for i in range(cell_start[0]-1, cell_end[0])],
header=None,
index_col=0,
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(cell_start[1]-1)]
)
return df.fillna("NA").T.to_dict(orient="list")
def create_column_header_dict(
book,
sheet=0,
column_header=1,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [1, column_header+1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[i for i in range(cell_start[0]-1, cell_end[0])],
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(column_header-1)]+[i for i in range(column_header, cell_start[1]-1)]
)
return df.fillna("NA").to_dict(orient="list")
def create_line_list(
book,
sheet=0,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [1, 1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[i for i in range(cell_start[0]-1, cell_end[0])],
header=None,
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(cell_start[1]-1)]
)
return list(df.fillna("NA").T.to_dict(orient="list").values())
def create_column_list(
book,
sheet=0,
cell_start=None,
cell_end=[16384, 1048576],
):
if cell_start is None:
cell_start = [1, 1]
df = pd.read_excel(
book,
sheet_name=sheet,
usecols=[i for i in range(cell_start[0]-1, cell_end[0])],
header=None,
nrows=cell_end[1]-cell_start[1]+1,
skiprows=[i for i in range(cell_start[1]-1)]
)
return list(df.fillna("NA").to_dict(orient="list").values())使い方
create_line_and_column_header_dict()
使い方
create_line_and_coloumn_header_dict(
excel_file,
sheet=0
line_h=1,
column_h=1,
cell_start=None,
cell_end=[16384, 1048576],
)
excel_file: 読み込みたいエクセルファイルのパスを指定します
sheet: シート番号を指定します。デフォルトは0で、一番左のシートが指定されます
line_h: 行ヘッダの位置を指定します。デフォルトで1列目が行ヘッダになります
column_h: 列ヘッダの位置を指定します。デフォルトで1行目が列ヘッダになります
cell_start: 表の左上を指定します。[列, 行]
cell_end: 表の右下を指定します。[列, 行]
使用例
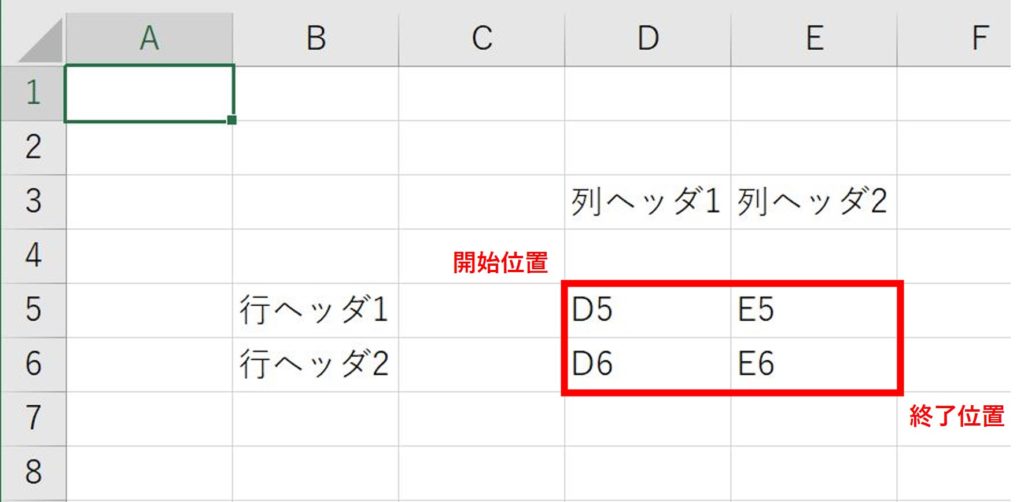
book.xlsx
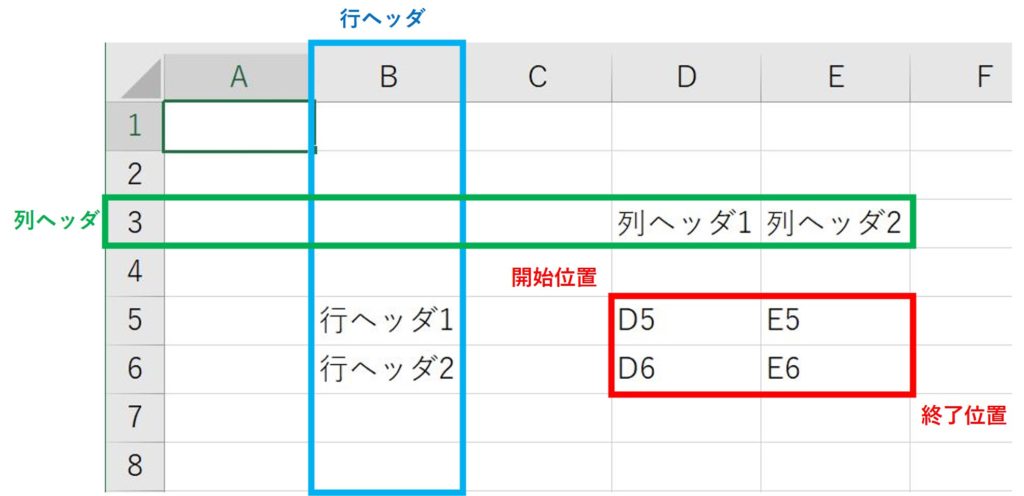
create_line_and_column_header_dict(
"book.xlsx",
sheet=0,
line_h=2,
column_h=3,
cell_start=[4, 5],
cell_end=[5, 6],
)結果
{'行ヘッダ1": {'列ヘッダ1': 'D5', '列ヘッダ2': 'E5', },
'行ヘッダ2": {'列ヘッダ1': 'D6', '列ヘッダ2': 'E6', }}create_line_header_dict()
使い方
create_line_header_dict(
excel_file,
sheet=0
line_h=1,
cell_start=None,
cell_end=[16384, 1048576],
)
excel_file: 読み込みたいエクセルファイルのパスを指定します
sheet: シート番号を指定します。デフォルトは0で、一番左のシートが指定されます
line_h: 行ヘッダの位置を指定します。デフォルトで1列目が行ヘッダになります
cell_start: 表の左上を指定します。[列, 行]
cell_end: 表の右下を指定します。[列, 行]
使用例
book.xlsx
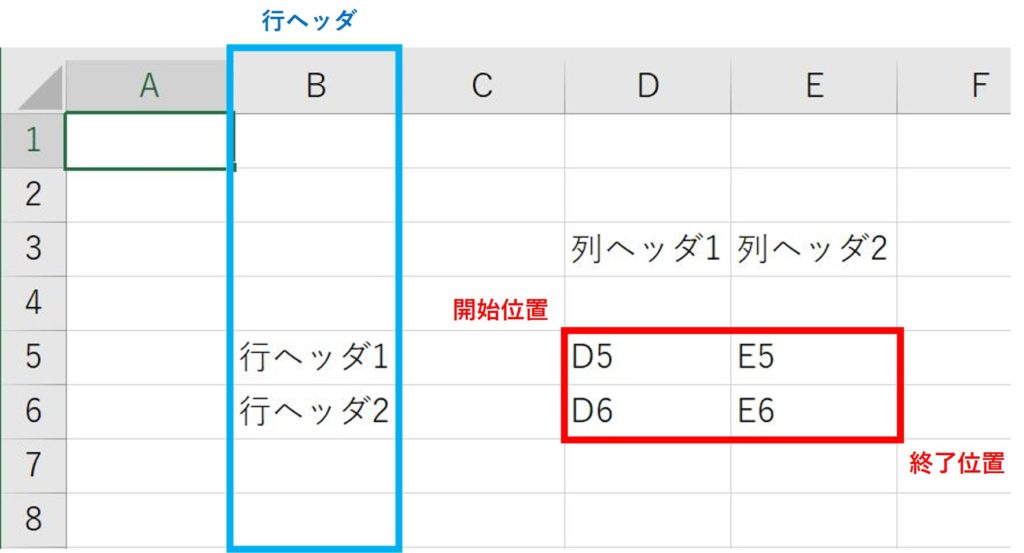
create_line_header_dict(
"book.xlsx",
sheet=0,
line_h=2,
cell_start=[4, 5],
cell_end=[5, 6],
)結果
{'行ヘッダ1": ['D5', 'E5'},
'行ヘッダ2": ['D6', 'E6']}create_column_header_dict()
使い方
create_coloumn_header_dict(
excel_file,
sheet=0
column_h=1,
cell_start=None,
cell_end=[16384, 1048576],
)
excel_file: 読み込みたいエクセルファイルのパスを指定します
sheet: シート番号を指定します。デフォルトは0で、一番左のシートが指定されます
column_h: 列ヘッダの位置を指定します。デフォルトで1行目が列ヘッダになります
cell_start: 表の左上を指定します。[列, 行]
cell_end: 表の右下を指定します。[列, 行]
使用例
book.xlsx
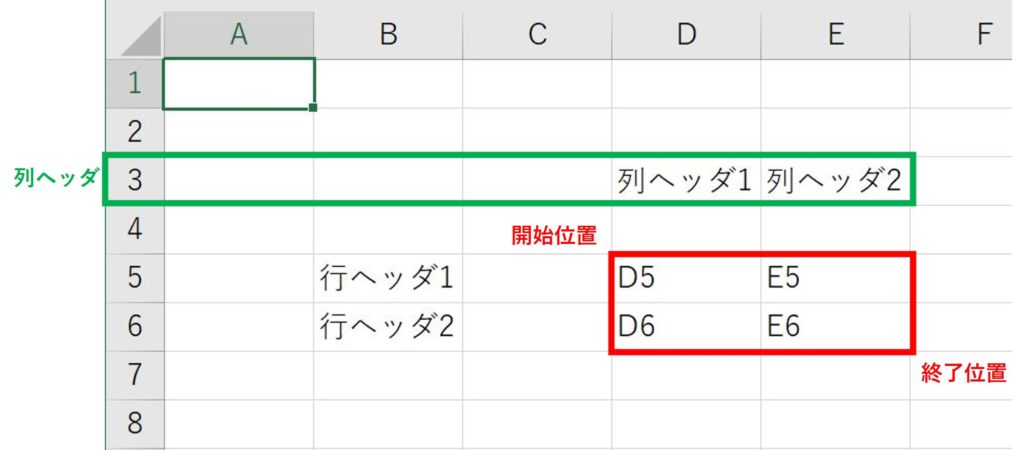
create_column_header_dict(
"book.xlsx",
sheet=0,
column_h=3,
cell_start=[4, 5],
cell_end=[5, 6],
)結果
{'列ヘッダ1": ['D5', 'D6'},
'列ヘッダ2": ['E5', 'E6']}create_line_list()
使い方
create_line_list(
excel_file,
sheet=0
cell_start=None,
cell_end=[16384, 1048576],
)
excel_file: 読み込みたいエクセルファイルのパスを指定します
sheet: シート番号を指定します。デフォルトは0で、一番左のシートが指定されます
cell_start: 表の左上を指定します。[列, 行]
cell_end: 表の右下を指定します。[列, 行]
使用例
book.xlsx
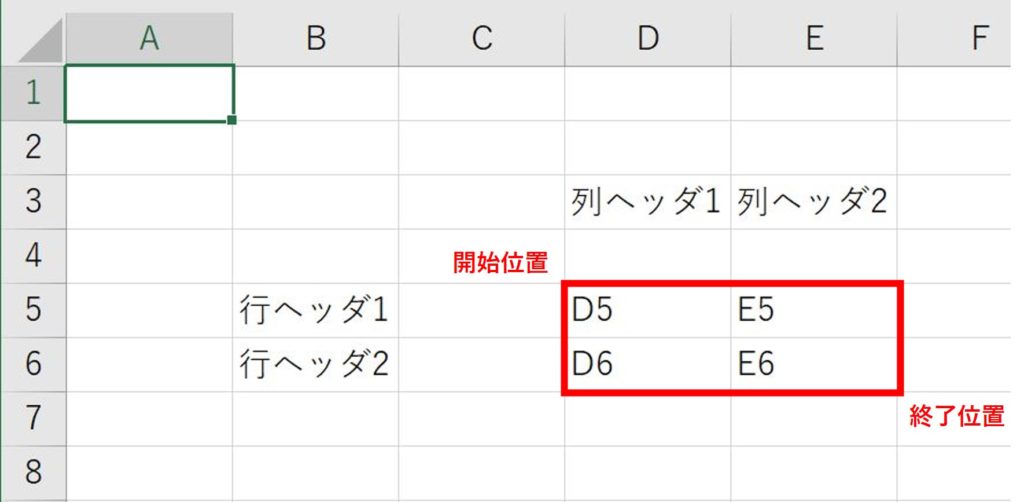
create_line_list(
"book.xlsx",
sheet=0,
cell_start=[4, 5],
cell_end=[5, 6],
)結果
[['D5', 'E5'], ['D6', 'E6']]create_column_list()
使い方
create_coloum_list(
excel_file,
sheet=0
cell_start=None,
cell_end=[16384, 1048576],
)
excel_file: 読み込みたいエクセルファイルのパスを指定します
sheet: シート番号を指定します。デフォルトは0で、一番左のシートが指定されます
cell_start: 表の左上を指定します。[列, 行]
cell_end: 表の右下を指定します。[列, 行]
使用例
book.xlsx
create_column_list(
"book.xlsx",
sheet=0,
cell_start=[4, 5],
cell_end=[5, 6],
)結果
[['D5', 'D6'], ['E5', 'E6']]
コメント