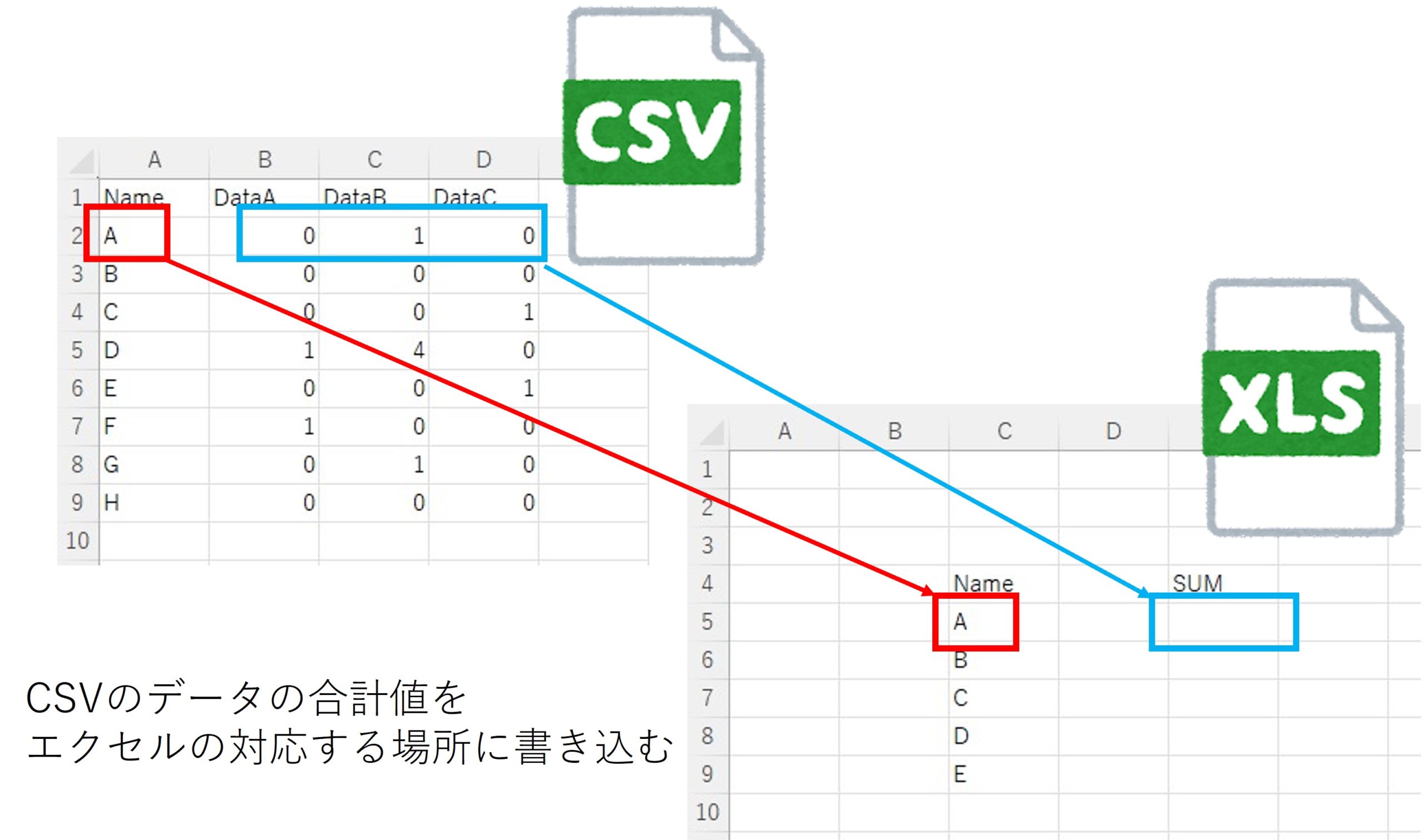
やりたいこと
CSVで管理されたデータをエクセルファイルの対応する場所に書き込みます。
ユースケース
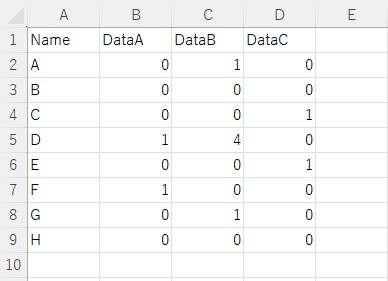
CSVにNameごとにDataA-Cが管理されています。
その合計値を、エクセルファイルのNameの対応する場所に書き込みます。
サンプルコード
データベース(input.csv)
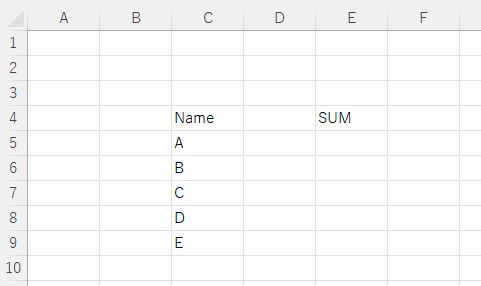
エクセルファイル(data.xlsx)
設定ファイル(conf.py)
csv = "input.csv" # CSVファイル
search_header = ["DataA", "DataB", "DataC"] # CSVファイルの読み込む列名
xlsx = "data.xlsx" # エクセルファイル
sheet = "Sheet1" # エクセルファイルのシート名
read_col = "C" # エクセルファイルとCSVファイルの対応する列
write_col = "E" # エクセルファイルで合計値を記入する列
start_row = 3 # エクセルファイルの読み込み開始行実行ファイル(sample.py)
from importlib import import_module
import argparse
import copy
import os
import openpyxl
import pandas as pd
def arg_parser():
"""Parser."""
parser = argparse.ArgumentParser()
parser.add_argument("conf")
return parser.parse_args()
def check_pass_fail(csv, search_header: list):
df = pd.read_csv(csv, index_col=0).T.to_dict()
for test in df.keys():
cnt = 0
for i in search_header:
cnt += int(df[test][i])
df[test].update({"Result": cnt})
return df
def write_result(data, xlsx, sheet, start_row, read_col, write_col):
wb = openpyxl.load_workbook(xlsx)
ws = wb[sheet]
for i, element in enumerate(ws[read_col][start_row:], start_row):
tmp = copy.deepcopy(data)
for test in tmp.keys():
if ws[write_col][i].value is not None:
continue
if element.value == test:
ws[write_col][i].value = data.pop(test)["Result"]
if data.keys():
print("WARNING: The Data Remain.")
for i in data.keys():
print(f"{i}")
wb.save(f"{xlsx}.new.xlsx")
if __name__ == "__main__":
args = arg_parser()
args = import_module(os.path.splitext(os.path.basename(args.conf))[0])
data = check_pass_fail(args.csv, args.search_header)
write_result(data, args.xlsx, args.sheet, args.start_row, args.read_col, args.write_col)実行結果
下記で実行します。
python sample.py conf.py
# 出力
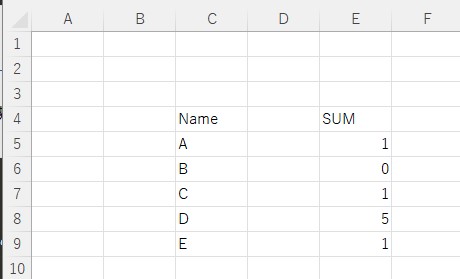
# WARNING: The Data Remain.
# F
# G
# H生成されるファイル(data.xlsx.new.xlsx)
まとめ
CSVファイルの読み込みとエクセルファイルの書き込みを使ってサンプルコードを作成しました。

コメント