
田中太郎
PythonでExcelファイルの差分を取ります。
行ヘッダ、列ヘッダ、行列ヘッダがある場合の3種類作成しました。
仕様
使用するパッケージ:pandas
入力:差分を取りたいエクセルファイルAとB
出力:差分のある行 or 列 or セル
行ヘッダがある場合のサンプルコード
入力となるエクセルファイルです
sampleA.xlsx
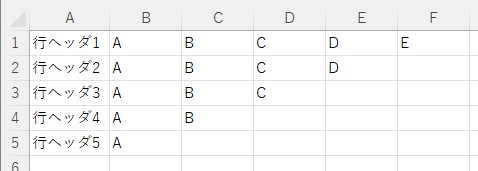
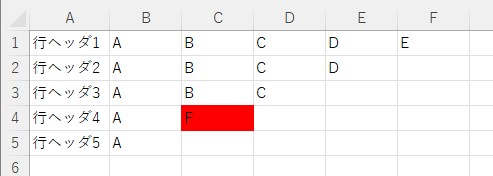
sampleB.xlsx
sample.py
import pandas as pd
def create_line_header_dict(input_excel):
df = pd.read_excel(input_excel, header=None, index_col=0)
return df.fillna("NA").T.to_dict(orient="list")
file_a = "sampleA.xlsx"
file_b = "sampleB.xlsx"
a = create_line_header_dict(file_a)
b = create_line_header_dict(file_b)
line = 0
for n, m in zip(a.values(), b.values()):
line+=1
if n != m:
print("{0} {1}".format(file_a, file_b))
print("({0}) {1} {2}".format(line, n, m))出力
sampleA.xlsx sampleB.xlsx
(4) ['A', 'B', 'NA', 'NA', 'NA'] ['A', 'F', 'NA', 'NA', 'NA']列ヘッダがある場合のサンプルコード
入力となるエクセルファイルです
sampleA.xlsx
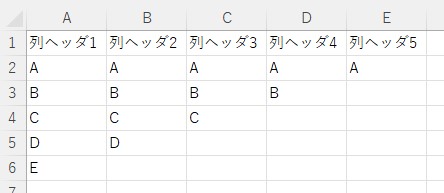
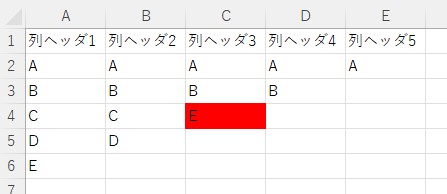
sampleB.xlsx
sample.py
import pandas as pd
def create_column_header_dict(input_excel):
df = pd.read_excel(input_excel)
return df.fillna("NA").to_dict(orient="list")
file_a = "sampleA.xlsx"
file_b = "sampleB.xlsx"
a = create_column_header_dict(file_a)
b = create_column_header_dict(file_b)
col = 0
for n, m in zip(a.values(), b.values()):
col+=1
if n != m:
print("{0} {1}".format(file_a, file_b))
print("({0}) {1} {2}".format(col, n, m))出力
sampleA.xlsx sampleB.xlsx
(3) ['A', 'B', 'C', 'NA', 'NA'] ['A', 'B', 'E', 'NA', 'NA']行列ヘッダがある場合のサンプルコード
入力となるエクセルファイルです
sampleA.xlsx
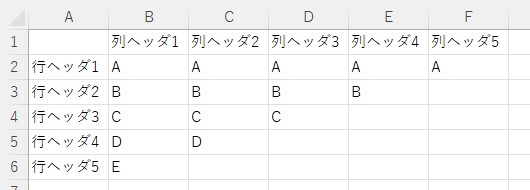
sampleB.xlsx
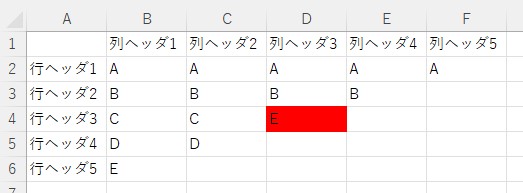
sample.py
import pandas as pd
def create_line_and_column_header_dict(input_excel):
df = pd.read_excel(input_excel, index_col=0)
return df.fillna("NA").to_dict(orient="index")
file_a = "sampleA.xlsx"
file_b = "sampleB.xlsx"
a = create_line_and_column_header_dict(file_a)
b = create_line_and_column_header_dict(file_b)
line = 0
for n, m in zip(a.values(), b.values()):
line+=1
col = 0
for l, o in zip(n.values(), m.values()):
col+=1
if l != o:
print("{0} {1}".format(file_a, file_b))
print("({0},{1}) {2} {3}".format(line, col, l, o))出力
sampleA.xlsx sampleB.xlsx
(3,3) C Eまとめ
Pythonでエクセルの差分を取るスクリプトを作成しました
コメント